One widely recommended approach to increase power is using a
within subject design. Indeed, you need fewer participants to detect a mean difference
between two conditions in a within-subjects design (in a dependent t-test) than in a between-subjects
design (in an independent t-test).
The reason is straightforward, but not always explained, and even less often expressed in the easy equation below. The sample size needed in within-designs (NW) relative to the sample
needed in between-designs (NB), assuming normal distributions, is (from Maxwell &
Delaney, 2004, p. 561, formula 45):
NW = NB
(1-ρ)/2
The “/2” part of the equation is due to the fact that in a two-condition
within design every participant provides two data-points. The extent to which
this reduces the sample size compared to a between-subject design depends on
the correlation between the two dependent variables, as indicated by the (1-ρ)
part of the equation. If the correlation is 0, a within-subject design simply
needs half as many participants as a between-subject design (e.g., 64 instead
128 participants). The higher the correlation, the larger the relative benefit
of within designs, and whenever the correlation is negative (up to -1) the
relative benefit disappears. Note than when the correlation is -1, you need 128
participants in a within-design and 128 participants in a between-design, but
in a within-design you will need to collect two measurements from each
participant, making a within design more work than a between-design. However, negative correlations between dependent variables in psychology are rare, and perfectly negative correlations will probably never occur.
So what does the correlation do so that it increases the power of
within designs, or reduces the number of participants you need? Let’s see what effect the correlation has on power by
simulating and plotting correlated data. In the R script below, I’m simulating two
measurements of IQ scores with a specific sample size (i.e., 10000), mean (i.e.,
100 vs 106), standard deviation (i.e., 15), and correlation between the two
measurements. The script generates three plots.
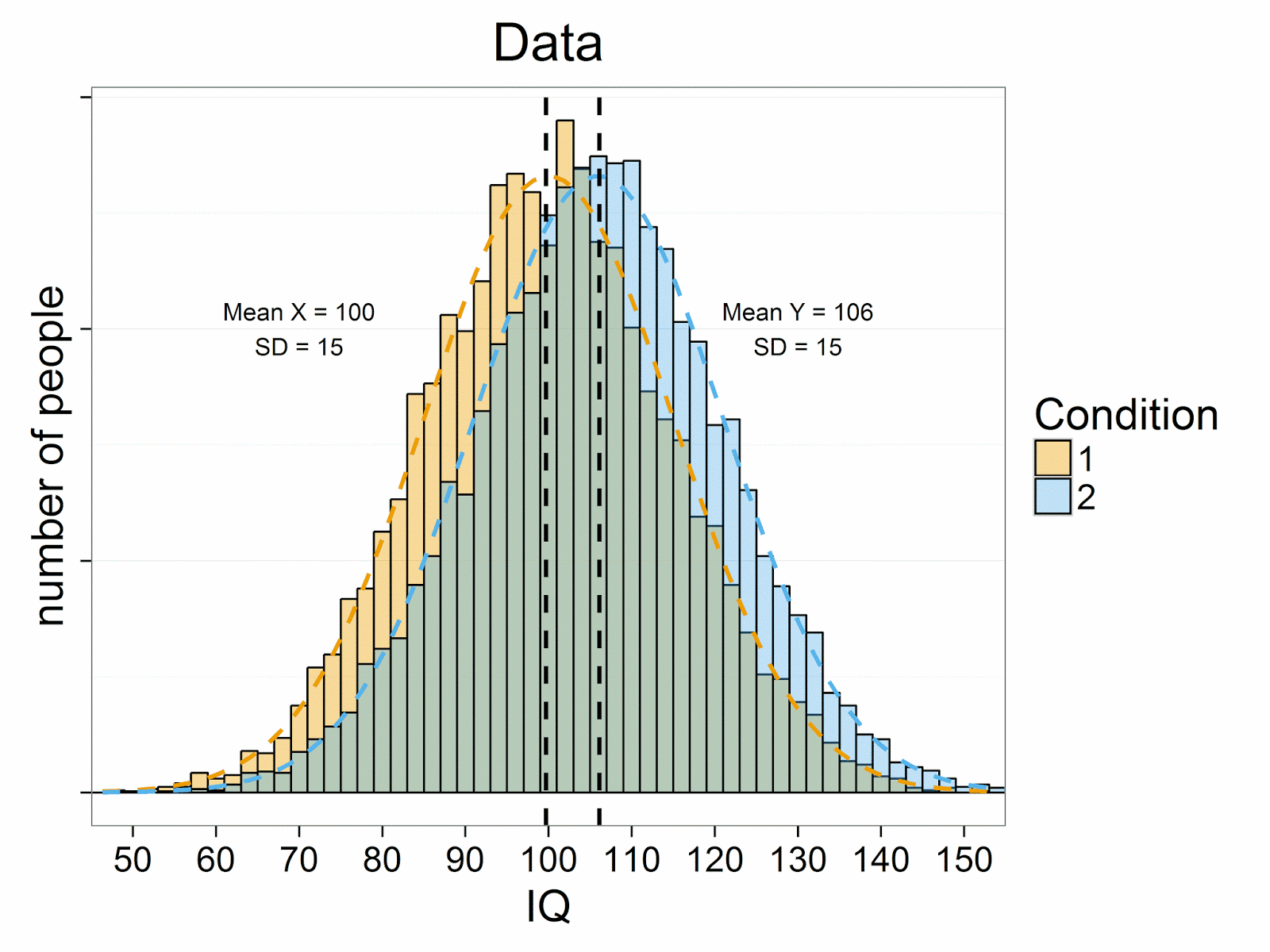
We will start with a simulation where the correlation
between measurements is 0. First, we see the two normally distributed IQ
measurements, with means of 100 and 106, and standard deviations of 15 (due to
the large sample size, the numbers equal the input in the simulation, although
small variation might still occur).
In the scatter plot, we can see that the correlation between
the measurements is indeed 0.

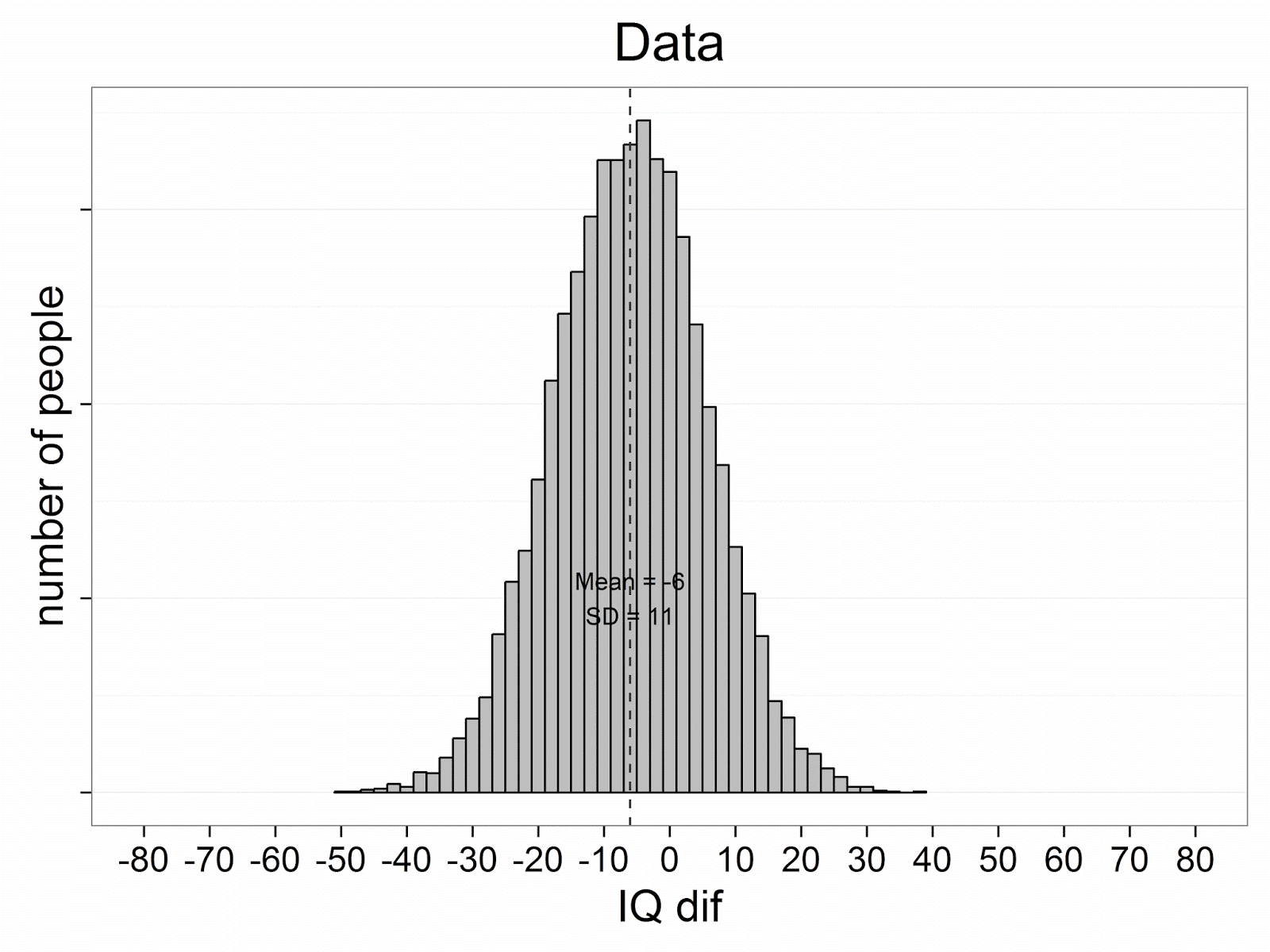
Now, let’s look at the distribution of the mean differences.
The mean difference is -6 (in line with the simulation settings), and the
standard deviation is 21. This is also as expected. The standard deviation of
the difference scores is √2 times as large as the standard deviation in each
measurement, and indeed, 15*√2 = 21.21, which is rounded to 21.
This situation where the correlation between measurements is zero equals the
situation in an independent t-test,
where the correlation between measurements is not taken into account.

Now let’s increase the correlation between dependent
variables to 0.7.
Nothing has changed when we plot the means:

The correlation between measurements is now strongly
positive:

The important difference lies in the standard deviation of
the difference scores. The SD = 11 instead of 21 in the simulation above.
Because the standardized effect size is the difference divided by the standard
deviation, the effect size (Cohen’s dz in within designs) is larger in this
test than in the test above.
We can make the correlation more extreme, by increasing the
correlation to 0.99, after which the standard deviation of the difference
scores is only 2.

If you run the R code below, you will see that if you set the
correlation to a negative value, the standard deviation of the difference scores actually increases.
I like to think of dependent variables in within-designs as dance
partners. If they are well-coordinated (or highly correlated), one person steps
to the left, and the other person steps to the left the same distance. If there
is no coordination (or no correlation), when one dance partner steps to the
left, the other dance partner is just as likely to move to the wrong direction
as to the right direction. Such a dance couple will take up a lot more space on
the dance floor.
You see that the correlation between dependent variables is
an important aspect of within designs. I recommend explicitly reporting the
correlation between dependent variables in within designs (e.g., participants responded significantly slower (M = 390, SD = 44) when they used their feet than when they used their hands (M = 371, SD = 44, r = .953), t(17) = 5.98, p < 0.001, Hedges' g =
0.43, Mdiff = 19, 95% CI
[12; 26]).
Since most dependent variables in within designs in
psychology are positively correlated, within designs will greatly increase the
power you can achieve given the sample size you have available. Use within-designs when
possible, but weigh the benefits of higher power against the downsides of order
effects or carryover effects that might be problematic in a within-subject
design. Maxwell and Delaney's book (Chapter 11) has a good discussion of this topic.
Maxwell, S. E., & Delaney, H. D. (2004). Designing experiments and analyzing data: a model comparison perspective (2nd ed). Mahwah, N.J: Lawrence Erlbaum Associates.